
Artificial Intelligence, Corporate Data, and the New European Regulatory Landscape
Navigating Opportunities, Operational Challenges, and the "Compliant by Design" Approach between Proprietary and Open-Source Platforms

The rapid spread of generative artificial intelligence (Generative AI) technologies, such as well-known programs and open-source solutions (llama3, llamaindex, Qdrant) accessible via cloud platforms, has radically transformed the business environment. This scenario offers new and significant opportunities for the analysis and strategic utilization of corporate data. Organizations can now quickly develop customized solutions, such as chatbots for customer support or technical staff assistance.
In high-tech sectors, the use of artificial intelligence can improve the performance of energy systems while helping professionals design and refine installations. In this context, machine learning and deep learning can solve problems related to the use of energy systems, detecting anomalies, and optimizing energy production and consumption (Olabi et al., 2023).
Despite the relative ease of implementing these solutions, it is essential to consider aspects related to privacy and data usage, both data already present in corporate databases and data provided by users during application interaction. The General Data Protection Regulation (GDPR, 2016), in effect since 2018, and the AI Act, approved by the European Parliament in 2024, provide the essential normative framework upon which the design of these applications must be based. The management of artificial intelligence and big data, although bringing numerous advantages, requires a careful knowledge of the main concepts highlighted in both regulations. The managerial challenge consists of adopting a “compliant by design” approach (AI Compliant by design, Naaia, 2024) to harmonize technological development with the obligation to protect privacy and sensitive data, starting from the initial project phases. Companies that invest in transparency and ethical use of artificial intelligence can develop sustainable systems and gain a competitive advantage (Patil et al. 2024).

A crucial point of intersection between the two regulations is the emphasis on transparency and explainability of automated systems. The GDPR includes the definition of “right to explanation,” requiring automated systems to be interpretable and necessitating the ability to trace back to the data and logical reasoning that led to a specific result. The AI Act, which places great emphasis on transparency and “explainability”, can integrate with the norms already foreseen by the GDPR (L. Metikoš e J. Ausloos, 2024). The AI Act aims to promote transparency by establishing that AI systems and their results must be understandable even to non-experts (R. Schwartmann et al., 2024). GDPR Article 22, which governs data processing in automated decision-making processes, integrates with the AI Act in sections regulating AI systems involving profiling or the use of sensitive data, thus dealing with high-risk systems (Falletta et al., 2024). These discussions may outline a new “right to interpretability” within continental legislation (Gallese, 2023). Furthermore, the concepts of Data Protection Impact Assessment (DPIA) under the GDPR and the Fundamental Rights Impact Assessment (FRIA) under the AI Act show significant analogies (T. Rintamäki et al., 2024), both aimed at mitigating risks before a high-risk application is implemented.
To address regulatory complexities and ensure operational flexibility, adopting a dual-track strategy is often recommended, developing systems both on proprietary platforms (such as custom ChatGPT versions, GPTs) and on open-source solutions (like llama3) hosted on the cloud. The dual-track approach also allows for true comparative analysis (A/B testing) of the two platforms’ performance. Transparency is a characteristic of both the AI Act and the GDPR (AI Act e Gdpr, Agenda Digitale, 2024) and is essential for preserving the trust of stakeholders (Ledro et al., 2023), especially in sectors like Customer Relationship Management (CRM) where chatbots are employed (Khneyzer et al., 2024).
At the managerial level, implementation requires rigorous data governance, establishing clear protocols for data collection, storage, and processing, including the anonymization of personal data and the use of encryption techniques. It is crucial to acknowledge that large language models, given their probabilistic nature, can generate inaccurate or misleading responses (hallucinations); therefore, systems must operate under constant human supervision. Staff training is a non-negotiable element that must cover not only the technical aspects but also the ethical and regulatory principles of the GDPR and the AI Act, preparing employees to recognize risks and intervene when necessary. Given the mutable nature of AI systems, AI Act Article 14, for example, requires a physical person to constantly supervise AI systems (Reinforcement Learning by Human Factor/Supervision),. Adopting a proactive and transparent approach to AI, in line with the AI Act and the GDPR, is not just a legal obligation but a determining factor for system sustainability and a competitive advantage.
Open-Source Models, Vector Databases, and Retrieval-Augmented Generation (RAG): A Brief Technical Explanation
The mention of open-source solutions such as llama3, llamaindex, and Qdrant highlights a clear trend toward adopting flexible and customizable platforms, in contrast to proprietary solutions (such as OpenAI’s GPT models). This path is often preferred by companies aiming to maintain tighter control over their data and ensure regulatory compliance [1].
Open-Source Language Models: Llama, Mixtral, and DeepSeek
The landscape of freely accessible Large Language Models (LLMs) with permissive licenses (open-weight/open-source) is dominated by giants like Meta, with its Llama family, and by innovative startups that are pushing the boundaries of efficiency and performance:
Mixtral (Mistral AI): This French startup has gained global attention by releasing extremely powerful models under the Apache 2.0 license, which allows for free commercial use. The flagship model, Mixtral 8x7B, utilizes an advanced architecture known as Mixture of Experts (MoE). In practice, while having a high total number of parameters (46.7 billion), it activates only a fraction (12.9 billion) for each input token. This approach enables performance comparable to or superior to closed models like GPT-3.5, with inference speed (response generation) up to six times faster and at significantly lower costs. This efficiency is crucial for on-premise implementation, which is strategically important for data security and GDPR compliance, allowing execution on accessible hardware.
DeepSeek: Coming from China, the DeepSeek laboratory has released LLMs (such as DeepSeek-V3 or DeepSeek-R1) that challenge Western leaders in terms of performance, particularly in mathematical reasoning and code generation. DeepSeek has distinguished itself by achieving high performance with significantly lower training costs, also often implementing the MoE architecture. Similar to Mistral, DeepSeek models support free use and execution on consumer hardware, making them an economically advantageous alternative for companies wishing to implement AI without depending on large proprietary cloud infrastructures.
Vector Databases and RAG (Retrieval-Augmented Generation)
The use of open-source language models for specific business tasks is almost always associated with implementing the Retrieval-Augmented Generation (RAG) technique. This methodology is essential for instructing a pre-trained model (such as Llama 3 or Mixtral) with a company’s specific knowledge base, without having to perform a costly and complex fine-tuning cycle.
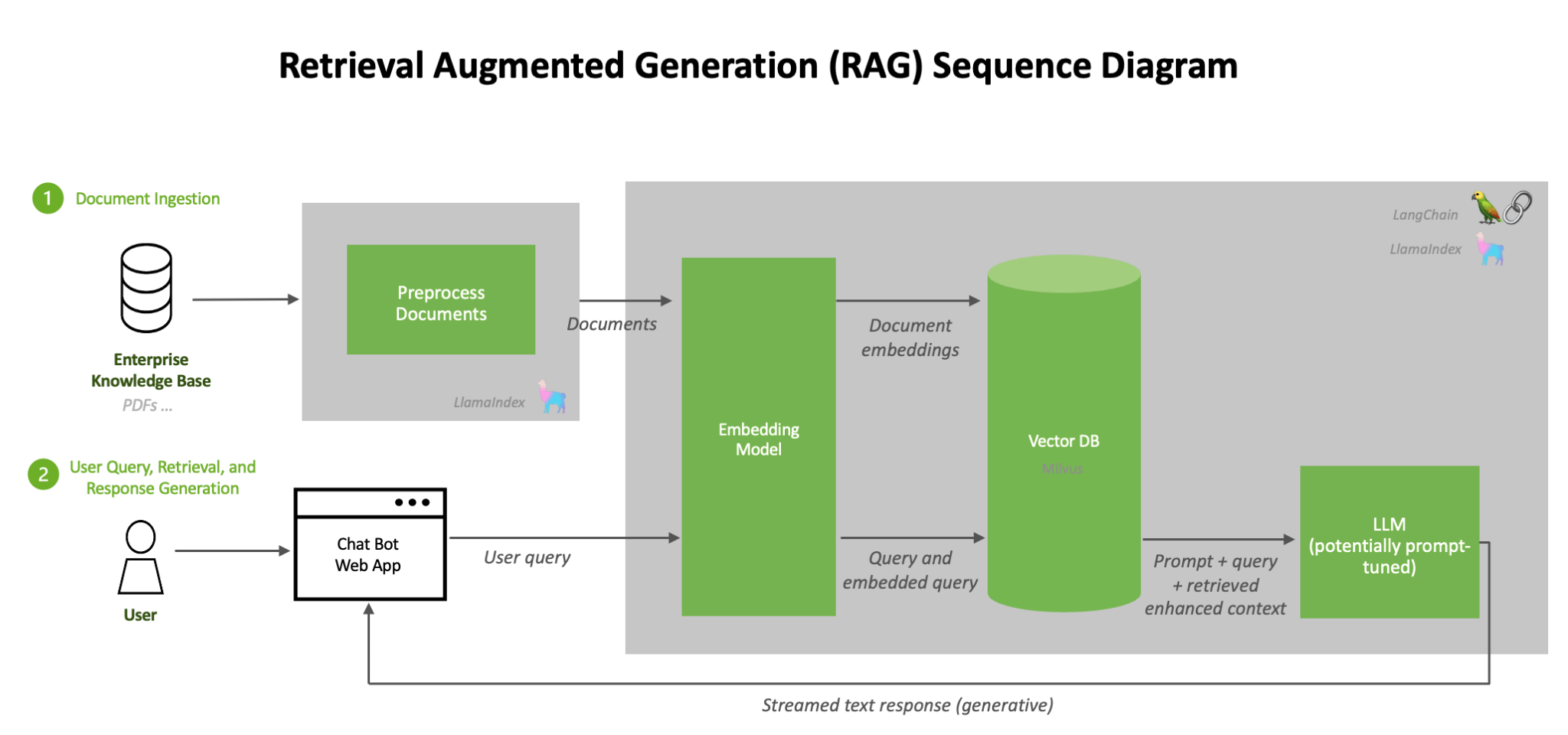
The RAG process consists of three key components:
Knowledge Base and Embeddings: Company data (documents, manuals, contracts) are converted into numerical vectors, known as embeddings, which represent the semantic meaning of the content.
Vector Database (e.g., Qdrant): These embeddings are stored in a dedicated vector database (such as Qdrant), which is optimized for rapid semantic retrieval. When the user enters a query, it too is converted into a vector. The vector database searches for and retrieves company documents (text “chunks”) whose vector is semantically closest to that of the query.
Generator (LLM): The language model (for example, Llama 3) receives the original query plus the relevant text retrieved from the vector database. In this way, the model can generate an accurate response based on company facts, significantly reducing the risk of “hallucinations” (generated but incorrect responses).
The RAG approach, in combination with open-source models, offers a balance between performance, customization, cost-effectiveness, and, above all, greater control over the source of data used, facilitating the adoption of a “compliant by design” approach.
📢 Disclaimer
Please note that the mention of specific Artificial Intelligence tools and models (such as llama3, Mixtral, DeepSeek, Qdrant, GPTs, etc.) is for educational, technical, and illustrative purposes only. There is no commercial affiliation, partnership, or economic endorsement between the author and the companies or proprietary open-source projects providing these services.
References
AI Act e Gdpr: come si integrano le norme sulla protezione dei dati, Agenda Digitale. Available at: https://www.agendadigitale.eu/sicurezza/privacy/ai-act-e-gdpr-come-si-integrano-le-norme-sulla-protezione-dei-dati/
AI Compliant by design, Naaia. Available at: https://naaia.ai/navigating-ai-design-with-a-new-compass-compliant-by-design-ai-systems/,
P. Falletta and A. Marsano, «Intelligenza artificiale e protezione dei dati personali: il rapporto tra Regolamento europeo sull’intelligenza artificiale e GDPR», Rivista italiana di informatica e diritto, vol. 6, fasc. 1, Art. fasc. 1, doi: 10.32091/RIID0155.,
C. Gallese, «The AI Act Proposal: a New Right to Technical Interpretability?», Social Science Research Network, Rochester, NY: 4398206. doi: 10.2139/ssrn.4398206.,
C. G. Granmar, «AI-Based Decision-Making and the Human Oversight Requirement Under the AI Act», in YSEC Yearbook of Socio-Economic Constitutions 2023: Law and the Governance of Artificial Intelligence, E. Gill-Pedro and A. Moberg, Eds., Cham: Springer Nature Switzerland, 2024, pp. 181-209. doi: 10.1007/16495 2024 68.,
W. E. Kedi, C. Ejimuda, C. Idemudia, and T. I. Ijomah, «AI Chatbot integration in SME marketing platforms: Improving customer interaction and service efficiency», International Journal of Management & Entrepreneurship Research, vol. 6, fasc. 7, Art. fasc. 7, doi: 10.51594/ijmer.v6i7.1327.,
C. Khneyzer, Z. Boustany, and J. Dagher, «AI-Driven Chatbots in CRM: Economic and Managerial Implications across Industries», Administrative Sciences, vol. 14, fasc. 8, Art. fasc. 8, doi: 10.3390/admsci14080182.,
Cristina Ledro, Anna Nosella, Ilaria Dalla Pozza, «Integration of AI in CRM: Challenges and guidelines - ScienceDirect», December 2023, Available at: https://www.sciencedirect.com/science/article/pii/S2199853123002536,
L. Metikoš and J. Ausloos, «The Right to an Explanation in Practice: Insights from Case Law for the GDPR and the AI Act», OSF. doi: 10.31219/osf.io/ezgxf.,
A. G. Olabi, M. A. Abdelkareem, and H. Jouhara, “Energy digitalization: Main categories, applications, merits, and barriers,” Energy, vol. 271, p. 126899, doi: 10.1016/j.energy.2023.126899.,
T. Rintamäki, D. Golpayegani, E. Celeste, D. Lewis, and H. J. Pandit, «High-Risk Categorisations in GDPR vs AI Act: Overlaps and Implications», OSF. doi: 10.31219/osf.io/6qhzj.,
R. Schwartmann, T. Keber, K. Zenner, and S. Kurth, «Data Protection Aspects of the Use of Artificial Intelligence - Initial overview of the intersection between GDPR and AI Act», Computer Law Review International, vol. 25, fasc. 5, pp. 145-150, doi: 10.9785/cri-2024-250503.
References for the section “Open-Source Models, Vector Databases, and Retrieval-Augmented Generation (RAG)”
Agenda Digitale, "AI per i cittadini, a che punto siamo in Ue: il caso Mistral" https://www.agendadigitale.eu/cultura-digitale/ai-per-i-cittadini-a-che-punto-siamo-in-ue-il-caso-mistral/.
Mistral AI Team, "Mixtral of experts," Mistral AI Blog, 11 dicembre 2023. Available at: https://mistral.ai/news/mixtral-of-experts.
«Introducing Meta Llama 3: The most capable openly available LLM to date», Meta AI. Disponibile su: https://ai.meta.com/blog/meta-llama-3/
Agenda Digitale, "Ai gen per il project manager: l’esperimento con Deepseek e Mistral" https://www.agendadigitale.eu/procurement/ai-gen-per-il-project-manager-lesperimento-con-deepseek-e-mistral/.
IBM, "DeepSeek: comprendere l'hype," 24 marzo 2025. Available at: https://www.ibm.com/it-it/think/topics/deepseek.
P. B. Consulting, "DeepSeek la guida completa. Perchè non è un problema di privacy," 2 febbraio 2025.
Lewis, P. et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," ArXiv abs/2005.11401, 2020.
Amazon Web Services (AWS), "What is RAG? - Retrieval-Augmented Generation AI Explained." Available at: https://aws.amazon.com/what-is/retrieval-augmented-generation/.
NVIDIA Blog, "What Is Retrieval-Augmented Generation aka RAG," 31 gennaio 2025. Available at: https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/.
K2view, "LLM vector database: Why it's not enough for RAG." https://www.k2view.com/blog/llm-vector-database/
lakeFS, "Best 17 Vector Databases for 2025 [Top Picks]," 20 ottobre 2025. Available at: https://lakefs.io/blog/best-vector-databases/.